

🔥 聚焦
VGGT:Meta与牛津大学提出视觉几何Transformer,单次前馈预测完整3D场景信息,荣获CVPR 2025最佳论文奖: Meta与牛津大学联合提出的VGGT (Visual Geometry Grounded Transformer) 成为CVPR 2025唯一最佳论文。该模型基于Vision Transformer,采用交替“全局-帧内”自注意力机制,能在单次前馈中端到端预测包括相机内外参数、深度图、点云图和3D轨迹在内的完整3D场景信息。VGGT仅通过大量3D标注数据自学习,无需几何归纳偏置,在处理1至200张图像输入时表现优异,性能超越多种现有几何或深度学习方法,展现了在3D视觉领域的广泛应用潜力 (来源: 量子位)

英伟达CEO黄仁勋与Anthropic CEO对AI发展的观点碰撞: 英伟达CEO黄仁勋在巴黎的一次新闻发布会上表示,他几乎不同意Anthropic CEO Dario Amodei关于AI的所有观点。黄仁勋指出Amodei认为AI过于危险,应由少数公司控制;AI成本高昂,其他公司不应涉足;以及AI将导致大规模失业。黄仁勋反驳称,AI是重要技术,应安全负责地公开发展,而非在封闭环境中进行,并强调开放性对于安全的重要性 (来源: hardmaru)
SafeKey框架提升大型推理模型安全性,风险率降低9.6%: 加州大学圣克鲁兹分校、伯克利分校、思科研究及耶鲁大学的研究团队提出SafeKey框架,旨在增强大型推理模型(LRMs)的安全性。研究发现模型“越狱”与未能有效利用早期的“关键句”安全信号有关。SafeKey通过“双通路安全头”放大安全信号,并通过“查询遮蔽建模”强迫模型依赖自身理解进行安全决策。实验表明,SafeKey在不显著影响模型核心能力(甚至略有提升)的前提下,能将危险回答率降低9.6%,尤其在面对未知攻击时表现更佳 (来源: 量子位)

Waymo研究表明自动驾驶系统性能随数据和计算规模呈幂律增长: Waymo发布了一项基于50万小时驾驶数据的综合研究,揭示了其自动驾驶系统中运动预测质量与训练计算量之间存在幂律关系,这与大型语言模型(LLM)的扩展规律相似。研究强调数据规模对于提升模型性能至关重要,同时增加推理计算量也能提高模型处理复杂驾驶场景的能力。这项研究首次表明,通过增加训练数据和计算资源可以改善真实世界的自动驾驶性能 (来源: zacharynado)
🎯 动向
字节跳动发布豆包大模型1.6及多款AI应用,强调组合能力与产品落地: 字节跳动近期密集发布豆包大模型1.6、视频生成模型Seedance 1.0 Pro、语音播客及实时语音模型等一系列AI产品。豆包1.6提升了多模态处理和操作能力,支持边想边搜和DeepResearch,并能进行图形界面操作。Seedance 1.0 Pro在视频生成的连贯性和稳定性上表现突出,支持10秒1080p视频生成。字节的策略更侧重于将AI能力整合成可直接运行的应用,并嵌入现有产品(如豆包APP、火山方舟),强调组合能力和快速产品化,而非单纯追求单一模型参数的领先。其定价策略也更具性价比,旨在降低AI使用门槛 (来源: 36氪)
腾讯混元3D 2.1模型开源,主打PBR纹理与消费级显卡适配: 腾讯在CVPR大会上宣布开源其最新的3D生成模型混元3D 2.1。该模型在几何精度和纹理细节上进行了双重优化,特别引入了PBR(基于物理的渲染)纹理生成技术,能高质量渲染皮革、金属、陶瓷等复杂材质,视觉效果逼真。混元3D 2.1实现了全链路开源,包括模型权重、训练代码和数据处理流程,并支持消费级显卡运行及一键部署,旨在推动3D内容创作的普及 (来源: 量子位)

Perplexity AI 积极改进 Deep Research 功能以回应用户反馈: Perplexity AI 首席执行官 Arav Srinivas 表示,团队认真听取了关于其 Deep Research 功能的负面反馈,并已着手进行改进。部分改进已在生产环境中上线,用户应能感受到体验提升。未来,Deep Research 和 Labs 功能将被整合到 Comet 产品中,旨在通过利用个人情境和数据优化用户的决策过程 (来源: AravSrinivas)
Anthropic研究揭示多智能体系统可显著提升任务表现: Anthropic发布的研究表明,采用多智能体系统(如Opus作为主智能体,Sonnet作为子智能体)处理任务,其表现比单独使用Opus提升了90%。这种协同工作的模式类似于人类社会通过分工协作大幅提高生产力。该研究详细介绍了如何构建有效的多智能体研究系统,并分享了其评估方法,包括使用LLM作为裁判。然而,有评论指出,报告中描述的Claude研究方法可能存在搜索深度不足的问题 (来源: zacharynado、omarsar0、nrehiew_)
研究指出大型语言模型推理能力受限于“不熟悉度”而非“复杂度”: François Chollet指出,大型语言模型(LRM)的推理能力并非在达到某一“复杂度”或“步骤数”阈值时崩溃,而是在面对“不熟悉”的任务时失效,且这个不熟悉度阈值非常低。模型可以解决训练/调整阶段覆盖过的极其复杂的任务,但即使是简单的新颖任务(如ARC 2任务)也可能失败。在熟悉问题(如汉诺塔)上观察到的步骤/复杂度阈值,实际上是通过增加问题变量来制造“新颖性”的结果 (来源: fchollet、jeremyphoward)
Sakana AI推出Text-to-LoRA (T2L) 超网络模型: Sakana AI 发布了 Text-to-LoRA (T2L),这是一种新型超网络,能够根据任务的文本描述快速为大型语言模型生成新的LoRA适配器。T2L不仅可以压缩多个现有LoRA,还能在训练后即时创建新的LoRA,为任务特定模型的快速定制提供了新途径。该研究将在ICML 2025上展示 (来源: TheTuringPost)
英伟达Cosmos-Predict2 (2B模型)展现出色图像生成能力: Nvidia的Cosmos-Predict2,一个20亿参数的模型,被定位为“物理AI的世界基础模型平台”,在艺术图像生成方面表现出令人印象深刻的能力。尽管其基础数据集可能并非最佳,但模型结构良好,生成的图像质量与14B参数版本相差不大,仅在细节和提示词遵循度上略逊一筹,显示了小型模型在特定优化下的潜力 (来源: teortaxesTex)
MIT研发新算法使无人机能自主规避风暴: MIT开发出一种新的算法,赋予无人机(UAVs)类似“大脑”的决策能力,使其能够实时分析天气状况并自主规划路径以规避风暴。这项技术有望提升无人机在复杂气象条件下的飞行安全性和任务执行效率 (来源: Ronald_vanLoon)
Meta研究:GPT风格语言模型每参数记忆3.6比特信息: Meta的一项新研究计算得出,GPT风格的语言模型每个参数能够记忆约3.6比特的信息。该研究通过测量模型记忆的总比特数量(基于香农1953年的理论)来评估其记忆容量,并观察到记忆与数据规模之间呈现特定的曲线关系 (来源: jxmnop)
OpenRouter发布LLM在结构化输出(JSON)任务中的违规率排名: OpenRouter根据过去一周顶级结构化输出请求中检测到的JSON违规百分比,对各大LLM进行了排名。结果显示,Qwen、Mistral和GPT-4o-mini表现较好,JSON违规率较低。而DeepSeek v3和Sonnet 4的违规率则超过20%,表明在精确遵循JSON格式方面仍有较大提升空间。目前尚不清楚造成这种差异的具体模式原因 (来源: xanderatallah、teortaxesTex)
蚂蚁集团推出统一多模态模型Ming-Omni: 蚂蚁集团发布了Ming-Omni系列模型,这是一个统一的多模态模型,能够进行跨文本、图像、音频和视频的感知与生成。其轻量级版本Ming-Lite-Omni采用MoE架构,激活参数仅2.8B,具备高质量图像生成和自然语音合成能力,并已在Hugging Face上以MIT许可证开源 (来源: teortaxesTex、_akhaliq)
中国启蒙AI芯片工具在数天内完成处理器设计,超越工程师效率: 中国研发的AI芯片设计工具“启蒙”(QiMeng)展示了其高效的处理器设计能力,能在短短数天内完成传统工程师需要更长时间才能完成的设计任务。这标志着AI在芯片设计自动化领域的潜力,有望加速芯片研发周期并降低成本 (来源: Ronald_vanLoon)
Hao AI Lab的o3-pro模型在LLM游戏基准测试中表现优异: Hao AI Lab的o3-pro模型在Lmgame Bench(一个用于评估大型语言模型游戏能力的基准测试)中取得了显著进展。在俄罗斯方块和推箱子游戏中,o3-pro均达到SOTA水平,并远超其前代o3模型。特别是在俄罗斯方块中,o3-pro能够清除8行以上,显示出其具备规划能力,而其他模型则在少数几行后即陷入困境 (来源: clefourrier)
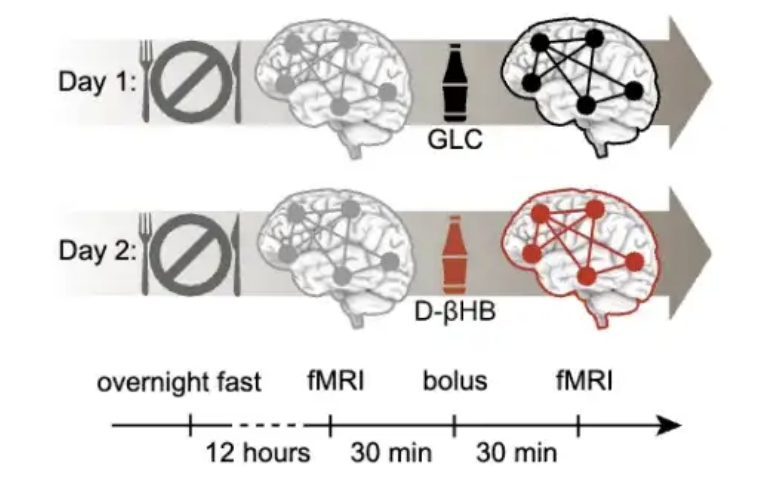
研究发现40岁是预防大脑衰老的关键窗口期,酮体干预效果显著: 一项发表于PNAS的研究通过分析近2万人的脑扫描数据,发现大脑衰老并非线性过程,而是呈S形曲线,与胰岛素抵抗增加相关。研究指出,约40岁是大脑网络不稳定性开始加速的时期,而60多岁时衰老速度最快。实验表明,酮体(D-βHB)能绕过胰岛素抵抗为神经元供能,对稳定大脑网络有显著作用,尤其在40-59岁年龄段干预效果最佳,为中年期大脑保健提供了新思路 (来源: 量子位)
🧰 工具
The Browser Company推出AI原生浏览器Dia测试版: Arc浏览器开发商The Browser Company发布了其首款AI原生浏览器Dia的内测版。Dia的最大亮点是允许用户直接与任何网页内容(包括YouTube视频、FigJam、谷歌日历等)进行聊天交互,无需打开ChatGPT等外部AI工具。它能自动从标签页获取上下文,支持多网页信息整合与比较、计划制定、内容创作等功能。目前仅支持MacOS,旨在提供更简洁、AI优先的浏览体验 (来源: 36氪)
LangChain推出本地AI播客生成器: LangChain发布了一款本地AI播客生成器,该系统使用LangChain和Ollama构建,能够将文本转换为多语言播客。它结合了文本摘要和语音生成技术,实现了无缝的播客创作流程。用户可以参考提供的教程学习如何使用该工具 (来源: LangChainAI、hwchase17)
Davia:将Python应用和LangGraph智能体快速转换为Web应用: Davia是一个能将Python应用程序和LangGraph智能体即时转换为精美Web应用的工具,无需编写任何前端代码。它基于FastAPI构建,能自动生成交互式用户界面,让开发者专注于Python逻辑的实现 (来源: LangChainAI、Hacubu)
Tensorlake与LangChain集成,实现文档结构化处理: Tensorlake宣布与LangChain集成,使LangGraph智能体能够利用Tensorlake强大的多模态处理系统,将非结构化文档转换为结构化数据。这一集成为处理复杂文档提供了新的解决方案 (来源: LangChainAI、hwchase17)
夸克发布国内首个高考志愿大模型及免费志愿报告功能: 夸克推出了国内首个高考志愿大模型,并上线了免费的“志愿报告”功能。该模型基于Agent运行模式,能模拟专家决策过程,结合实时更新的“高考知识库”(覆盖2900+高校、近1600个本科专业及就业等信息),为考生生成包含“冲、稳、保”三个层次的个性化志愿填报方案。此举旨在利用AI技术降低高考志愿填报的门槛和成本,改变传统高价咨询的局面 (来源: 量子位)

Task Orchestrator:为Claude Code打造的MCP项目管理工具: 开发者jpicklyk创建了名为Task Orchestrator的MCP(Machine-Level Code Programming)工具,旨在解决Claude Code在处理复杂项目时容易“分心”和忘记上下文的问题。该工具通过赋予Claude持久化记忆、结构化项目管理(项目→特性→任务)、AI原生模板、智能依赖关系和进度追踪能力,使其更像一个有条理的工程伙伴。项目已在GitHub开源 (来源: Reddit r/ClaudeAI)
ATLAS:赋予Claude Code自感知能力的软件工程AI伙伴: 开发者syahiidkamil创建了ATLAS项目,旨在将Claude Code转变为一个具备初步自我意识、记忆、身份和专业标准的软件工程AI伙伴。ATLAS能够维护项目上下文,自我管理知识,随代码提交而进化,并主动请求代码审查,从而促进用户与AI之间形成更自然的协作和审查流程。项目已在GitHub开源,旨在帮助用户和AI共同维护更高质量的代码 (来源: Reddit r/ClaudeAI)
Observer:本地运行的屏幕监控AI助手: Observer是一款可以本地运行的AI工具,能够监控用户屏幕活动。通过教程可以学习如何在家用服务器上自托管Observer,实现对屏幕内容的AI辅助分析或交互 (来源: Reddit r/LocalLLaMA)
VantaAI:具备记忆与情感逻辑的本地AI助手项目分享: 一位开发者分享了其个人项目VantaAI,这是一个旨在完全离线运行的本地AI助手。VantaAI模拟了情感记忆、情绪波动和个人身份等特征,拥有基于对话上下文进化的长期记忆、追踪情绪变化的“情绪图谱”以及将自身视为故事主角的叙事驱动记忆聚类。该项目使用自定义Vulkan后端进行模型推理和训练,并支持基于个性的响应和插件热重载 (来源: Reddit r/LocalLLaMA)
📚 学习
Hamel Husain与Shreya Shankar合著AI Evals书籍并开设课程: Hamel Husain和Shreya Shankar合作撰写了一本关于AI评估(Evals)的书籍,并开设了相关课程。该书第一章节和完整目录已提供预览,内容涵盖从理论到实践的AI评估方法。课程还邀请了多位行业专家作为客座讲师,旨在帮助学员提升AI系统评估能力。该课程受到广泛好评,被认为是目前关于AI评估最全面的资源之一 (来源: HamelHusain、HamelHusain)
DSPy框架:为复杂语言模型程序提供高级编程抽象: Stanford NLP团队强调DSPy框架旨在成为与计算机进行精确交互的高带宽语言。DSPy允许开发者构建和优化复杂的多阶段语言模型程序(Compound AI Systems),支持递归、异常处理、嵌套控制流等任意程序结构,而不仅仅是简单的“链”或“流”。其优化器致力于调整任意计算机程序中指令、演示和权重,这些程序可以任意调用一个或多个LLM (来源: stanfordnlp)
Terence Tao做客Lex Fridman播客,探讨数学、物理难题与AI未来: 著名数学家陶哲轩(Terence Tao)接受Lex Fridman采访,深入探讨了数学和物理学中最具挑战性的问题,如纳维-斯托克斯方程、P vs NP问题等,并展望了人工智能在辅助解决这些难题方面的潜力。播客内容还涉及AI辅助定理证明、Lean编程语言、DeepMind的AlphaProof以及AI获得菲尔兹奖的可能性等话题
Phillip Isola团队发布免费在线计算机视觉教材: Phillip Isola及其团队将其撰写的计算机视觉教材免费在线发布。该教材网站 (visionbook.mit.edu) 正在开发互动组件,如搜索功能和与LLM的集成(测试版),旨在为学习者提供更便捷的学习资源,并鼓励用户通过GitHub issues帮助改进教材内容 (来源: jeremyphoward、natolambert)
Hugging Face推出MCP入门课程: Hugging Face与Theodora Chu合作,推出了一门新的MCP(Master Control Program,可能指代AI Agent或多智能体系统控制)入门课程。该课程旨在帮助学习者了解和掌握MCP相关知识和技能 (来源: huggingface、ClementDelangue)
DINOv2与文本对齐研究(dino.txt)亮相CVPR 2025: 一项名为dino.txt的研究在CVPR 2025上展示,该研究致力于将冻结的DINOv2特征与文本字幕对齐,以低成本实现图像级和补丁级的视觉语言对齐。这使得模型能够同时利用DINOv2高质量的视觉特征和CLIP风格的视觉语言对齐能力 (来源: TimDarcet、andersonbcdefg)
💼 商业
腾讯系AI独角兽明略科技冲刺港股IPO,估值120亿: 数据智能应用软件公司明略科技(前身为“汇智控股”)已向港交所递交招股书。该公司由北大数院校友吴明辉于2005年创立,专注于利用大模型、行业知识和多模态数据为企业提供营销和运营决策支持。其核心产品包括秒针系统、金数据等,服务客户包括宝洁、麦当劳等135家世界500强企业。腾讯为其第一大股东,持股27.33%。公司在2024年1月完成IPO前最后一轮融资后,估值约120亿元人民币 (来源: 量子位)

OpenAI与玩具制造商美泰(Mattel)达成战略合作,共同开发AI智能玩具: OpenAI宣布与全球知名玩具制造商美泰(Mattel)合作,将共同开发搭载人工智能技术的智能玩具。此次合作旨在将OpenAI的AI技术应用于适合年龄段的玩具体验中,颠覆传统游戏方式。美泰旗下拥有芭比娃娃、风火轮等知名IP。双方承诺在合作中严格保障儿童安全与隐私。美泰还将把OpenAI的AI工具(如ChatGPT Enterprise)整合到其业务运营中,以加强产品开发和创新 (来源: 36氪)
企业搜索初创公司Glean完成1.5亿美元后期融资: 企业搜索初创公司Glean宣布获得1.5亿美元的后期融资,使其估值达到72亿美元。Glean利用AI技术帮助企业员工更高效地在公司内部繁杂的SaaS应用和数据源中查找信息 (来源: dl_weekly)
🌟 社区
Hugging Face举办全球LeRobot机器人黑客马拉松,推动开源机器人技术发展: Hugging Face在全球多个城市(包括迈阿密、亚琛、里昂、慕尼黑、班加罗尔、伦敦、巴黎、洛杉矶、旧金山湾区等)同步举办LeRobot机器人黑客马拉松。活动旨在推动开源机器人技术和AI在机器人领域的应用,参与者利用LeRobot平台和提供的硬件(如机械臂、深度相机)进行开发。活动吸引了大量开发者参与,共同探索机器人学习、视觉语言模型(VLA)训练等前沿技术,并涌现出如迷你glambot、自动生物实验室助手、茶艺机器人等创意项目 (来源: ClementDelangue、huggingface、ClementDelangue)
关于Claude Code能力与使用方法的讨论: 社交媒体上出现关于Claude Code能力的讨论。有用户认为,尽管Claude Code宣称其部分代码由自身生成,但这并不等同于完全的“自举”,类比VSCode的代码也主要由VSCode编写。强调在使用Claude Code这类工具时,应采取小步迭代、审查代码、版本管理等基本原则,并具备主导程序设计和任务划分的能力。当生成代码出现问题时,应先尝试让其修复,无效则回滚。另有用户指出,Atlassian推出的Rizo被认为是Claude Code的竞争者,并提供每日2000万免费tokens (来源: dotey、dotey、Reddit r/ClaudeAI)
AI对就业市场影响的观点:加剧分化,顶尖人才受益: BrivaelLp认为,当前AI技术(如代码生成工具)能将普通开发者的效率提升5倍,而顶尖开发者则能提升100倍。这将导致企业更倾向于招聘经验丰富的顶尖人才,而减少对初级人员的需求。AI可能加剧各行业内部的“马太效应”,顶尖10%的从业者将迎来黄金时代,而中间层则面临压力,呼应了“平庸者无市场”的观点 (来源: BrivaelLp)
本地LLM的优势与应用场景讨论: Reddit社区讨论了在本地运行大型语言模型(LLM)的优势。除了隐私保护和潜在的成本节省(尽管硬件投入可能不菲),用户强调了对模型的完全控制、定制化能力(如修改模型、集成RAG)、无API限制、离线使用以及更少的审查机制。本地LLM也为学习和实验提供了便利,例如有用户在本地部署视觉LLM处理家庭照片,或开发具有记忆和情感逻辑的AI助手 (来源: Reddit r/LocalLLaMA)
关于LLM是否具备真正推理能力的讨论持续: 社区中对于大型语言模型(LLM)是否真正具备推理能力,以及其能力的边界在哪里,持续存在讨论。François Chollet认为LLM的推理能力受限于“不熟悉度”而非“复杂度”。另有观点认为,LLM只是基于大量训练数据进行模式匹配和“回忆”,并非真正的思考。这些讨论反映了对当前AI技术本质和未来发展方向的深入思考 (来源: fchollet、francoisfleuret、vikhyatk)
AI在医疗诊断中展现潜力,但用户需谨慎对待: Reddit上有用户分享了ChatGPT帮助其妻子纠正医生误诊的案例,引发了关于AI在医疗领域应用的讨论。虽然AI在辅助诊断,特别是罕见病识别和医学影像分析方面显示出潜力,但社区也强调ChatGPT等通用AI并非专业医疗工具,其信息可能不准确或过时。用户在采纳AI提供的医疗建议时应极其谨慎,并务必咨询专业医生。有用户建议通过提问AI自身是否绝对可靠来验证其局限性 (来源: Reddit r/ChatGPT、gdb)
AI生成内容质量与用户偏好引发讨论: 有观点认为,大型语言模型(LLM)的某些“不良”特性,如过于冗长或迎合用户,实际上是用户偏好的结果。类比于人们偏爱高糖分的加工食品,AI公司为优化LMArena等平台的评分,可能导致模型输出趋向于取悦用户而非追求极致的准确性和简洁性。HamelHusain也分享了其在提示中加入的写作指南,以对抗AI生成内容中的“废话”,强调需要积极删除冗余信息 (来源: scaling01、jeremyphoward、HamelHusain)
AI Agent在特定任务自动化中的价值凸显: Jerry Liu指出,尽管通用聊天助手在创意激荡方面表现出色,但在执行具体任务时仍需大量提示工程。他认为,构建能够出色完成单一特定任务的自动化AI Agent系统具有巨大价值。通过将特定流程编码到Agent工作流中,可以实现更高效、更可控的自动化。LlamaIndex正致力于支持这类专业代码工作流,未来也可能出现更多无代码UI/UX来构建此类自动化Agent (来源: jerryjliu0)
💡 其他
CVPR 2025青年学者奖授予谢赛宁与苏昊: 在CVPR 2025大会上,谢赛宁和苏昊荣获青年学者奖。该奖项旨在表彰获得博士学位不超过7年的早期研究者在计算机视觉领域的杰出贡献。苏昊(李飞飞博士生)参与了ImageNet项目,谢赛宁则与何恺明合作完成了ResNeXt并参与了MAE项目,均为CV领域的重要工作 (来源: 量子位)
Nikon SLM NXG激光打印机或推动制造业变革: Nikon推出的SLM NXG激光打印机,其外观与DUV(深紫外光刻)设备惊人相似。这款打印机被认为有潜力引发一场创成式制造业革命,尤其对于特定领域。尽管Nikon在DUV竞赛中输给了ASML,但其激光源技术仍在持续发展并应用于新的制造领域 (来源: teortaxesTex)
AI图像生成在2022年至2025年间的显著进步: Reddit用户分享了2022年和2025年使用AI根据相同提示词(《瑞克和莫蒂》主题)生成的图像对比。2022年的图像在人物细节(如手部、鼻子)和整体协调性上存在明显缺陷,而2025年的图像则大幅改进,显示了AI图像生成技术在短短几年内的飞速发展。尽管仍有用户指出新图像中角色手部细节仍不完美,但整体进步是显而易见的 (来源: Reddit r/artificial)
本篇文章来源于微信公众号: AI热点掘金 ,仅供学习,如有侵权请及时联系删除
