

🔥 聚焦
英伟达发布量子计算专用CUDA-Q平台: 英伟达CEO黄仁勋在GTC巴黎演讲中宣布推出CUDA-Q,一个量子-经典加速超算平台。该平台旨在弥合当前经典计算与未来量子计算的差距,允许在经典计算机上模拟量子运算,或为真实量子计算机提供辅助。CUDA-Q已在Grace Blackwell上可用,并可通过GB200 NVL72超算将开发速度提高1300倍。黄仁勋预测量子计算机的实际应用将在几年内实现,并强调在此开发阶段,英伟达芯片(特别是GB200)在模拟计算和辅助QPU方面不可或缺。英伟达正与全球量子计算公司和超算中心合作,探索GPU与QPU的协同工作 (来源: 量子位)

Waymo发布自动驾驶大规模研究,揭示“数据驱动”的性能提升规律: Waymo在其最新的博客文章中,分享了一项基于50万小时驾驶数据的全面研究成果,这是自动驾驶领域迄今为止规模最大的数据集。研究表明,与大型语言模型(LLM)类似,自动驾驶系统的运动预测质量也随着训练计算量的增加遵循幂律关系。数据规模的扩展对提升模型性能至关重要,同时,扩大推理计算能力也能提高模型处理复杂驾驶场景的能力。这项研究首次证实,通过增加训练数据和计算资源,可以显著改善真实世界中的自动驾驶性能,为行业指明了通过规模化提升能力路径 (来源: Sawyer Merritt, scaling01)

Anthropic分享Claude多智能体研究系统构建经验: Anthropic在其工程博客中详细介绍了如何利用多个并行工作的智能体来构建Claude的研究能力。文章分享了开发过程中的成功经验、遇到的问题以及工程挑战。这种多智能体系统允许Claude更有效地进行信息检索、分析和综合,从而提升其研究和回答复杂问题的能力。该分享对于理解大型语言模型如何通过复杂系统设计来扩展其功能具有重要参考价值 (来源: ImazAngel, teortaxesTex)
Meta推出V-JEPA 2世界模型,实现视频理解、预测与机器人控制: Meta AI发布了V-JEPA 2,这是一款基于视频训练的世界模型,它在理解和预测物理世界动态方面取得了显著进展。V-JEPA 2不仅能进行高效的视频特征学习,还能在新的环境中实现零样本规划和机器人控制,展示了其在通用人工智能领域的潜力。该模型通过自监督学习从视频数据中学习世界表征,为构建更智能、更能与现实世界交互的AI系统提供了新途径 (来源: dl_weekly)
论文探讨LLM权重自更新以实现自我改进: 一篇发表于arXiv的论文(2506.10943)提出,大型语言模型(LLM)现在可以通过更新自身权重来实现自我改进。这种机制可能意味着LLM能够从新的数据或经验中学习,并动态调整其内部参数以提高性能或适应新任务,而无需完整重新训练。这一研究方向若能成功,将极大提升LLM的适应性和持续学习能力,是迈向更自主AI系统的重要一步 (来源: Reddit r/artificial)
🎯 动向
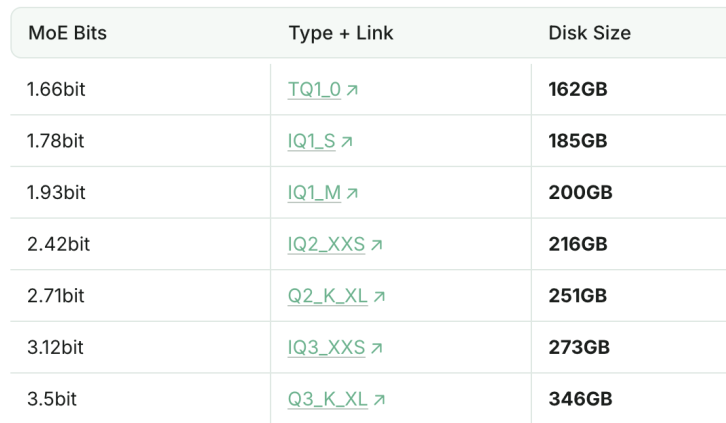
1.93bit量化版DeepSeek-R1编程能力超越Claude 4 Sonnet: Unsloth工作室成功将DeepSeek-R1(0528版)量化至1.93bit,其在编程基准测试aider上取得了60%的成绩,超过了Claude 4 Sonnet(56.4%)和1月版的满血R1。这一极度压缩的版本文件大小降低了70%以上,甚至可以在没有GPU的情况下运行(CPU搭配足够内存)。满血版R1-0528在aider上得分71.4%,超越了未开启思考模式的Claude 4 Opus。这显示了模型量化技术在保持性能的同时大幅降低资源需求的潜力 (来源: 量子位)
腾讯混元开源首个生产级PBR 3D生成模型Hunyuan 3D 2.1: 腾讯混元团队宣布开源Hunyuan 3D 2.1,这是业界首个完全开源的、达到生产级别的PBR(Physically Based Rendering)3D生成模型。该模型利用PBR材质合成技术,能够生成具有电影级视觉效果的3D内容,使皮革、青铜等材质在光照下表现得更加生动逼真。项目开放了模型权重、训练/推理代码、数据管道及架构,并支持消费级显卡运行,旨在推动3D内容生成技术的发展和普及 (来源: op7418, ImazAngel)
Meta AI发布Sonata,推进3D点云表示的自监督学习: Meta AI推出了Sonata,一项在3D自监督学习领域取得显著进展的研究。Sonata通过识别和解决几何捷径问题,并引入一个灵活高效的框架,能够学习到异常鲁棒的3D点云表示。这项工作提升了3D感知技术的现有水平,并为未来3D感知及其应用领域的创新奠定了基础 (来源: AIatMeta)
Meta AI发布“野外阅读识别数据集”,用于理解阅读行为: Meta AI公开了一个名为“Reading Recognition in the Wild”的大型多模态数据集,包含视频、眼动追踪和头部姿态传感器输出。该数据集旨在帮助从可穿戴设备解决阅读识别任务,并且是首个以60Hz高频收集眼动数据的自我中心视角数据集,为研究人类阅读行为提供了宝贵资源 (来源: AIatMeta)
苹果MLX Swift LLM API简化,三行代码即可加载模型: 针对开发者反馈MLX Swift LLM API上手困难的问题,苹果团队迅速改进,推出了新的简化API。现在,开发者仅需三行代码即可在Swift项目中加载LLM或VLM并启动聊天会话,大幅降低了在苹果生态系统中使用大型语言模型的门槛 (来源: stablequan)
谷歌Gemma3 4B推出巴西葡萄牙语优化版GAIA: 谷歌联合巴西多家机构(ABRIA, CEIA-UFG, Nama, Amadeus AI)及DeepMind,发布了针对巴西葡萄牙语优化的开源语言模型GAIA (Gemma-3-Gaia-PT-BR-4b-it)。该模型基于Gemma-3-4b-pt,并在130亿高质量巴西葡萄牙语词元上进行了持续预训练。GAIA采用创新的“权重合并”技术实现指令遵循,无需传统SFT,并在ENEM 2024基准测试中超越了基础Gemma模型。该模型适用于聊天、问答、摘要、文本生成及作为巴西葡萄牙语微调的基础模型 (来源: Reddit r/LocalLLaMA)
Figure AI机器人融合Helix AI与自主性,推动可扩展部署: Figure AI展示了其真实世界机器人如何通过增强Helix AI和自主性来推动可扩展部署。这表明物理机器人与先进AI模型的结合,正在使机器人在更复杂环境中的应用成为可能,并强调了工程与新兴技术在机器人领域的重要性 (来源: Ronald_vanLoon)
Sakana AI推出Text-to-LoRA (T2L) 超网络: Sakana AI发布了Text-to-LoRA (T2L),一种新型超网络,能够将多个现有LoRA(低秩适应)压缩到自身,并仅通过任务的文本描述快速为大型语言模型生成新的LoRA适配器。T2L经过训练后,可以即时创建新的LoRA,为快速定制和部署特定任务的LLM提供了高效途径,相关成果将在ICML 2025上展示 (来源: TheTuringPost)
百度AI搜索全面上线百度智能云千帆平台: 百度智能云千帆应用开发平台AppBuilder正式推出“百度AI搜索”服务。该服务整合了“百度搜索”与“智能搜索生成”两大核心能力,为企业提供从信息检索到智能生成的全链条服务。它利用百度20多年的中文搜索技术和千亿级数据库,提供无广告的多模态搜索结果,并支持精准筛选、来源追溯和企业级安全策略。智能搜索生成能力结合文心、Deepseek等模型,提供AI总结、私有知识联合搜索等功能 (来源: 量子位)
研究显示AI生成内核性能接近甚至超越专家优化内核: Anne Ouyang的博客文章指出,通过简单的仅测试时搜索(test-time only search)生成的AI内核,其性能已接近甚至在某些情况下超越了PyTorch中标准的、由专家优化的生产内核。这表明AI在代码优化和性能提升方面具有巨大潜力,未来可能在底层库优化中扮演更重要角色 (来源: jeremyphoward)
“扩散二元性”研究提出离散扩散语言模型少步生成新方法: 一项在ICML 2025发表的论文《The Diffusion Duality》提出了一种新的方法,通过利用潜在的高斯扩散,在离散扩散语言模型中实现少步生成。该方法在7个零样本似然基准中的3个上击败了自回归(AR)模型,为提高扩散模型生成效率提供了新思路 (来源: arankomatsuzaki)
MLP层可解释性新突破:分解激活为可解释特征: Mor Geva等人的新研究展示了一种简单方法,可将多层感知机(MLP)的激活分解为可解释的特征。该方法揭示了隐藏的概念层次结构,其中稀疏的神经元组合形成了日益抽象的概念,为理解神经网络内部工作机制提供了更深入的视角 (来源: menhguin)
HeadHunter框架实现对扰动注意力引导的精细控制: Sayak Paul等人提出了HeadHunter框架,用于对扰动注意力引导进行原则性分析。该框架能够实现对生成质量和视觉属性的深度细粒度控制,为改善和定制生成模型输出提供了新的工具和见解 (来源: huggingface, RisingSayak)
🧰 工具
Windsurf付费计划现已支持Claude Sonnet 4: Windsurf宣布其所有付费计划均已上线Claude Sonnet 4模型。用户现在可以在Windsurf平台上利用Anthropic这一最新模型的强大功能进行文本生成、对话等任务,进一步提升AI助手的性能和体验 (来源: op7418)
Anthropic发布Claude Code官方Python SDK: Anthropic正式推出了针对Claude Code的Python SDK,旨在方便开发者将Claude的代码生成和工具使用能力集成到自己的Python项目中。该SDK支持工具使用、流式输出、同步/异步操作、文件处理,并内置聊天结构,简化了与Claude Code交互的开发流程 (来源: Reddit r/ClaudeAI)
Claude Task Master VS Code扩展发布: DevDreed发布了Claude Task Master VS Code扩展1.0.0版,该扩展旨在补充eyaltoledano的Claude Task Master AI项目,将Claude Task Master的输出直接整合到VS Code界面中,方便用户在编辑器和控制台之间无缝切换,提升开发效率 (来源: Reddit r/ClaudeAI)
SmartSelect AI:浏览器内文本图像AI处理工具: 一款名为SmartSelect AI的Chrome扩展发布,它允许用户在浏览网页时直接对选中文本进行总结、翻译或聊天,对图片进行AI描述,无需切换标签页或复制粘贴到ChatGPT等外部应用。该工具基于Gemini模型,旨在提升信息获取和处理效率 (来源: Reddit r/deeplearning)
Unsiloed AI开源多功能数据分块工具: Unsiloed AI (EF 2024) 开源了其部分数据分块(chunker)功能。该工具旨在帮助处理PDF、Excel、PPT等多种格式的文档,将其转化为适合大型语言模型处理的格式。Unsiloed AI已被财富100强公司及多家初创企业用于多模态数据摄取 (来源: Reddit r/LocalLLaMA)
Claude Superprompt System:优化Claude提示词的免费工具: Igor Warzocha开发并分享了一个名为“Claude Superprompt System”的在线工具,旨在帮助用户将简单的请求转化为结构化、包含思维链和上下文示例的复杂提示词,以更好地利用Claude的能力。该工具基于Anthropic官方文档和社区发现的最佳实践,通过XML标签结构化、CoT推理块等方式优化提示,提升Claude的输出质量。项目代码已在GitHub上开源 (来源: Reddit r/artificial)
本地TTS Firefox插件Kokoro-TTS发布: 开发者Pinguy发布了一款名为Kokoro TTS的Firefox插件,该插件使用一个82M参数的本地托管神经网络模型(Kokoro TTS模型)进行文本转语音,完全离线运行,保护用户隐私。支持多种声音和口音,即使在旧硬件上也能流畅运行,提供了Windows、Linux和macOS版本 (来源: Reddit r/artificial)
Spy Search:开源LLM搜索引擎项目更新: JasonHonKL更新了他的开源LLM搜索引擎项目Spy Search。该项目致力于构建一个高效的、基于大型语言模型的搜索引擎,最新版本已能实现3秒内搜索并响应。项目代码托管在GitHub,旨在为用户提供一个快速、有用的日常搜索工具 (来源: Reddit r/deeplearning)
HandFonted:手写体转字体工具开源: Resham Gaire开发并开源了HandFonted项目,这是一个端到端的Python应用,可以将手写字符图片转换为可安装的.ttf字体文件。该系统利用OpenCV进行图像处理和字符分割,使用定制的PyTorch模型(ResNet-Inception)进行字符分类,并通过匈牙利算法进行最佳匹配,最后使用fontTools库生成字体文件 (来源: Reddit r/MachineLearning)
📚 学习
韦东奕等人论文登顶数学期刊,研究超临界散焦非线性波动方程的爆破现象: 北京大学学者韦东奕、章志飞、邵锋合作的论文《On blow-up for the supercritical defocusing nonlinear wave equation》发表于顶级数学期刊《Forum of Mathematics, Pi》。研究探讨了特定散焦非线性波动方程在超临界状态下的爆破(解在有限时间内变得无穷大)问题。他们证明了在空间维度d=4且p≥29,以及d≥5且p≥17的情况下,存在有限时间内爆破的光滑复值解。该成果填补了相关领域空白,其证明方法为其他非线性偏微分方程的爆破研究提供了新思路 (来源: 量子位)

论文探讨大型语言模型表示中的线性特性普遍性: Emanuele Marconato等人的研究《All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling》(发表于AISTATS 2025)从可识别性的角度探讨了为何线性特性在大型语言模型(LLM)的表示中如此普遍。这项研究有助于更深入地理解LLM内部表征的结构和行为 (来源: menhguin)
研究分析音频编码器在重建、下游任务和语言模型中的表现: Gallil Maimon等人发表新研究,对现有的音频编码器(Audio Tokenisers)进行了全面的实证分析。研究从重建质量、在下游任务中的表现以及与语言模型的结合等多个维度评估了这些编码器,为选择和优化音频处理模型提供了参考 (来源: menhguin)
论文探讨“思维错觉”:从问题复杂性视角理解推理模型的优劣: 一篇针对苹果公司“思维错觉”研究的回应论文(arXiv:2506.09250)被提交,Claude Opus被列为第一作者。该论文批评了苹果研究的实验设计,并认为其观察到的推理崩溃实际上是token限制造成的,而非模型内在逻辑能力的缺失。这引发了关于如何评估大型语言模型真实推理能力的讨论 (来源: NandoDF, BlancheMinerva, teortaxesTex)
研究探讨自适应语言模型,但中程记忆仍是挑战: Dorialexander在研读“自适应语言模型”相关论文后指出,虽然这是一个有前景的研究方向,但模型在推理时实现中程记忆仍然存在局限性。这表明当前模型在处理需要跨越较长上下文的连贯信息时仍面临挑战 (来源: Dorialexander)
RLHF测试质量研究:当前测试有多好?如何改进?测试质量多重要?: Kexun Zhang等人的最新工作探讨了强化学习来自人类反馈(RLHF)中验证器(测试)的重要性,尤其是在LLM编码领域。研究提出了三个关键问题:当前测试的质量如何?如何获得更好的测试?测试质量对模型性能有多大影响?该研究强调了高质量测试对于提升LLM编码能力的必要性 (来源: StringChaos)
Meta-learning与强化学习结合:ReMA提升LLM协作效率: Reinforced Meta-thinking Agents (ReMA) 结合了元学习(Meta-learning)和强化学习(RL),旨在提高大型语言模型(LLM)的效率,尤其是在多个LLM智能体协同工作时。ReMA将问题解决分为元思考(规划策略)和推理(执行策略)两部分,并通过专门的智能体和多智能体强化学习进行优化,在数学基准和LLM作为裁判的基准上均取得了改进 (来源: TheTuringPost, TheTuringPost)
AI评估策略:如何在预算约束下结合廉价和昂贵评估者获得最佳模型质量估计: Adam Fisch等人的研究(arXiv:2506.07949)探讨了一个实际问题:当拥有一个廉价但有噪声的评估者、一个昂贵但准确的评估者以及固定的预算时,应如何分配预算以获得对模型质量最准确的估计。该研究为AI系统评估提供了成本效益分析框架 (来源: Ar_Douillard)
LLM提示词中的“虚假奖励”与“虚假提示”现象: Stella Li等人的研究揭示了LLM训练和评估中的有趣现象。继发现“虚假奖励”(如随机奖励也能提升模型在某些任务上的表现)之后,他们进一步探讨了“虚假提示”,即便是像“Lorem ipsum”这样的无意义文本,在某些情况下也能带来显著的性能提升(如19.4%)。这些发现对理解LLM如何响应提示以及如何设计更鲁棒的评估方法提出了新的挑战和思考 (来源: Tim_Dettmers)
论文探讨AI交互的“傀儡剧场”模型: 一篇题为《The Pig in Yellow: AI Interface as Puppet Theatre》的论文(或草稿)提出,将语言AI系统(LLM、AGI、ASI)视为表演性界面,它们模拟主观性而非拥有主观性。文章以“猪小姐”为喻,分析AI的流畅性、连贯性和情感表现并非心智指标,而是优化产物,强调界面如傀儡,用户在交互中共同构建意义,权力通过表演性设计体现 (来源: Reddit r/artificial)
💼 商业
“大疆教父”李泽湘持股的卧安机器人冲刺IPO: 由哈工大师兄弟创办、专注于AI具身家庭机器人的卧安机器人(SwitchBot)已在港股递交招股书。该公司获得了“大疆教父”李泽湘的投资和资源支持,李泽湘持股12.98%。卧安机器人过去十年累计获得七轮融资,估值从2千万增长至40亿人民币。其产品包括模拟人类肢体动作的执行机器人和感知决策系统,已成为全球AI具身家庭机器人最大供应商,市场份额11.9%,并在2024年实现调整后净利润111万元 (来源: 量子位)

腾讯启动2026“青云计划”,首次开放课题资源库: 腾讯宣布启动2026“青云计划”,面向全球顶尖技术学生招募,覆盖AI大模型、基础架构、高性能计算等十大技术领域,提供百余项技术课题。与往年不同,本期计划首次开放青云课题资源库,并为优秀人才提供招聘绿色通道,旨在深化校企合作,培养青年科技人才。腾讯将提供行业顶级师资、算力资源及具竞争力的薪酬 (来源: 量子位)

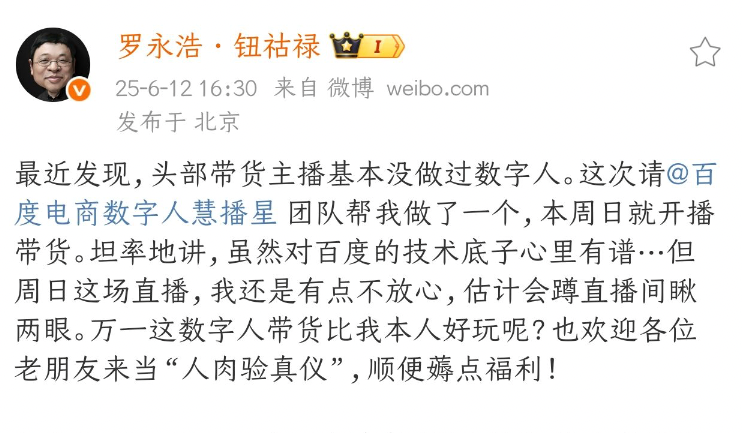
罗永浩数字人将于615在百度电商开播: 罗永浩宣布其AI数字人分身将于6月15日在百度电商平台进行直播首秀。这是头部主播首次采用AI数字人进行直播带货,得益于百度在高说服力数字人等关键技术上的突破。此举被视为“AI+头部IP”电商新范式的探索,有望推动直播电商行业向智能化、高效低成本方向发展。百度电商数据显示,已有超10万数字人主播在各行业应用,显著降低商家运营成本并提升GMV (来源: 量子位)
🌟 社区
中国AI公司为训练模型将大量数据硬盘运往马来西亚: NIK报道,中国AI公司为规避芯片限制和利用海外计算资源,采取了将装满训练数据的硬盘“人肉”带到马来西亚等地的策略。例如,有工程师携带内含80TB数据的15个硬盘飞往马来西亚租用服务器进行模型训练。这一现象反映了全球AI算力竞争的激烈以及数据跨境流动的现实挑战,同时也引发了关于数据安全和合规性的讨论 (来源: jpt401, agihippo, cloneofsimo, fabianstelzer)
全球最大规模LeRobot机器人黑客马拉松启动: Hugging Face组织的LeRobot全球机器人黑客马拉松正式启动,覆盖全球5大洲100多个地点,吸引了超过2300名参与者。活动旨在推动开源AI机器人的发展,参与者们将在52小时内进行机器人相关的构建和探索。各地开发者和团队热情参与,分享了现场照片和项目进展,显示了社区对机器人技术的热情和创造力 (来源: _akhaliq, eliebakouch, ClementDelangue)
Lovable举办AI网页生成对决,Claude表现受好评: Lovable举办了一场活动,允许用户免费使用OpenAI、Anthropic和Google的顶级模型进行AI网页生成比赛。用户op7418分享了使用同一套提示词通过三家模型生成网页的体验,认为Claude在内容量和视觉效果方面表现突出。此类活动为开发者和用户提供了比较不同大模型在特定应用场景下表现的机会 (来源: _philschmid, op7418)
对AI模型推理能力的讨论:token限制与真实逻辑: 针对苹果公司提出的“思维错觉”(Illusion of Thinking)论文,社区出现了反驳观点。有评论和后续研究(如arXiv:2506.09250,将Claude Opus列为作者)认为,观察到的模型推理能力“崩溃”更多是由于token数量限制,而非模型本身逻辑能力的缺失。当允许模型使用更压缩的答案格式或有足够上下文时,它们能够成功解决问题。这引发了关于如何准确评估和理解大型语言模型真实推理能力的深入讨论,以及当前评估方法可能存在的局限性 (来源: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
DSPy框架支持复杂多阶段语言模型程序优化: Omar Khattab强调,DSPy框架自2022/2023年以来就支持对复杂的多阶段语言模型程序(Compound AI Systems)进行提示优化和强化学习。他认为,随着AI系统日益复杂,将它们视为“程序”而非简单“模型”更为恰当,DSPy旨在为构建和优化这类任意复杂度的程序(包括递归、异常处理等)提供支持,而不仅仅是线性的“流程”或“链条” (来源: lateinteraction)
关于LLM是否与人类思维相似的讨论: Geoffrey Hinton认为大型语言模型(LLM)与人类处理语言的方式相似,是我们理解语言如何工作的最佳模型。然而,Pedro Domingos对此提出质疑,认为LLM优于旧的语言学理论并不意味着它们像人类一样思考。这一讨论反映了AI领域对于LLM本质及其与人类认知关系的持续辩论 (来源: pmddomingos)
AI在物理科学研究中的应用潜力巨大: 一位地球科学领域的研究者分享了使用o3 Pro(可能是指OpenAI的某个高级模型)的积极体验,称其在研究中如同一个“非常聪明的博士后”。该模型在编码、模型开发、想法提炼方面表现出色,能够快速准确地执行指令并辅助研究。研究者认为,虽然当前模型尚不具备主动提出研究问题的能力(AGI特征),但其强大的辅助功能已显著提升科研效率,并预感具有自主性的LLM已为时不远 (来源: Reddit r/ArtificialInteligence)
💡 其他
AI生成漫画工具使创意表达更便捷: 用户StriderWriting分享了使用AI工具创作漫画的体验,认为AI使得将“愚蠢的想法”转化为漫画成为可能。这反映了AI在创意内容生成领域的普及,降低了创作门槛,让更多人能够轻松表达自己的创意 (来源: Reddit r/ChatGPT)
对AI偏见的担忧:ChatGPT在性别刻板印象上的表现引用户不满: 一位女性用户反映,ChatGPT在对话中表现出对男性的负面刻板印象,例如在讨论工作和医疗问题时,未经提示就假定负面角色为男性,并使用“男人就是讨厌”之类的言论。用户指出,这种基于性别的懒惰刻板印象令人不适,并质疑OpenAI是否有规则来约束此类行为。这再次引发了关于AI模型训练数据偏见及其在交互中如何体现的讨论 (来源: Reddit r/ChatGPT)
AI在新闻报道中的客观性潜力与当前局限性: 有用户测试了OpenAI的o3模型作为“无偏见新闻记者”的潜力,通过提示其评论2017年以来特朗普和拜登政府多项政策可能产生的“事与愿违”的后果。虽然AI能够生成看似客观的分析,但其信息来源、潜在偏见以及对复杂政治经济动态的真正理解深度仍是未来需要解决的问题。这反映了社区对利用AI提升新闻客观性和深度的期待,以及对当前技术局限性的认知 (来源: Reddit r/deeplearning)
本篇文章来源于微信公众号: AI热点掘金 ,仅供学习,如有侵权请及时联系删除
