

🔥 聚焦
OpenAI 发布 o3-pro,号称史上最强模型,并大幅降低 o3 定价: OpenAI 正式推出其迄今最强大的推理模型 o3-pro,并已向 ChatGPT Pro 及 Team 用户开放,API 也同步上线。o3-pro 在科学、教育、编程、商业和写作辅助等领域表现优于前代,支持网页搜索、文件分析、视觉输入和 Python 编程等多种工具。其定价为输入每百万 tokens 20美元,输出80美元。同时,原 o3 模型价格大幅下调80%,调整后输入每百万 tokens 2美元,输出8美元,与 GPT-4o 持平。此举或将引发AI模型价格战,并推动AI在专业领域的深度应用,但 o3-pro 也存在响应时间较长、暂不支持临时对话等局限。(来源: OpenAI, sama, OpenAIDevs, scaling01, dotey)

Meta 成立“超级智能实验室”并巨资入股 Scale AI,力图重振 AI 竞争力: 据纽约时报等多方消息,Meta Platforms 正在重组其 AI 部门,成立新的“超级智能实验室”,并计划投资超过140亿美元收购数据标注公司 Scale AI 49%的股权。Scale AI 的联合创始人兼CEO Alexandr Wang 将加入Meta并领导该新实验室。此举旨在加速通用人工智能(AGI)的研发,提升 Meta 在 AI 领域的整体竞争力,尤其是在高质量数据处理和顶尖人才招募方面。这标志着 Meta AI 战略的重大调整,可能对行业竞争格局产生深远影响。(来源: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)
Mistral AI 发布首个推理模型系列 Magistral,包含开源版本: 法国AI初创公司Mistral AI推出了其首个专为推理设计的模型系列Magistral。该系列包括一个更强大的企业级闭源模型Magistral Medium和一个240亿参数的开源模型Magistral Small (Magistral-Small-2506),后者基于Apache 2.0许可证发布。这些模型在数学、编码和多语言推理方面表现出色,旨在提供更透明和领域特定的推理能力。Magistral Medium在Le Chat平台上的推理速度据称比竞争对手快10倍,而Magistral Small则为社区提供了强大的本地运行选项。(来源: Mistral AI, jxmnop, karminski3)
IBM 计划2028年建成大规模容错量子计算机 Starling: IBM 公布了其量子计算发展蓝图,计划于2028年建成名为 Starling 的大规模容错量子计算机,并期望在2029年通过云服务向用户开放。Starling 系统预计将包含约100个模块和200个逻辑量子比特,核心目标是实现有效的错误校正,这是当前量子计算领域面临的最大技术挑战之一。该机器将采用IBM的低密度奇偶校验码(LDPC)进行错误校正,并致力于实现实时错误诊断。若成功,这将是量子计算领域的重大突破,可能加速其在材料科学、药物研发等复杂问题上的应用。(来源: MIT Technology Review)
🎯 动向
苹果WWDC 2025 AI相关进展未能惊艳开发者: 苹果在WWDC 2025上发布了多项更新,包括全新的“液态玻璃”设计语言和Xcode 26集成ChatGPT等。然而,开发者社区普遍对其在人工智能方面的进展表示“未达预期”。尽管苹果首次向开发者开放其端侧AI模型,并推出了Foundation Models框架简化AI功能集成,但备受期待的新版Siri更新可能推迟至明年。分析师郭明錤指出,苹果AI战略占据中心,但技术上未见重大突破,市场预期管理成为关键。苹果似乎更侧重于改善用户界面和操作系统功能,而非在AI模型本身进行颠覆式创新。(来源: MIT Technology Review, jonst0kes, rowancheung)
五角大楼削减AI武器系统测试评估办公室规模: 美国国防部长Pete Hegseth宣布将国防部作战测试与评估主任办公室(DOT&E)的规模裁减一半,人员从94人降至约45人。该办公室负责测试和评估武器及AI系统的安全性和有效性,此次调整旨在“减少官僚机构臃肿和浪费性支出,提高杀伤力”。此举引发了关于AI军事应用安全性和有效性测试可能受到影响的担忧,尤其是在五角大楼正积极将AI技术(包括大语言模型)整合到各类军事系统中的背景下。(来源: MIT Technology Review)
OpenBMB 发布 MiniCPM-4 系列端侧高效大语言模型: OpenBMB(面壁智能)推出了 MiniCPM-4 系列模型,专为端侧设备设计,旨在实现超高效率运行。该系列包括 MiniCPM4-0.5B、MiniCPM4-8B(旗舰模型)、BitCPM4(1-bit量化模型)、专用于报告生成的 MiniCPM4-Survey 以及 MCP 专用模型 MiniCPM4-MCP。技术报告详细介绍了其高效模型架构(如InfLLM v2可训练稀疏注意力机制)、高效学习算法(如Model Wind Tunnel 2.0)以及高质量训练数据处理方法。这些模型现已在Hugging Face开放下载。(来源: _akhaliq, arankomatsuzaki, karminski3)
DatologyAI 发布仅通过数据管理即达SOTA水平的CLIP模型: DatologyAI 展示了其在多模态领域的最新研究成果,通过精细的数据管理(data curation)而非算法或架构创新,使其CLIP ViT-B/32模型在ImageNet 1k上达到了76.9%的准确率,超越了SigLIP2报告的74%。该方法同时带来了8倍的训练效率提升和2倍的推理效率提升。模型已公开发布,凸显了高质量数据在提升模型性能方面的巨大潜力。(来源: code_star, andersonbcdefg)
Krea AI 发布首个自研图像模型 Krea 1: Krea AI 推出了其首个图像模型 Krea 1,该模型在美学控制和图像质量方面表现出色,拥有广泛的艺术知识储备,并支持风格参考和自定义训练。Krea 1 旨在提升图像的真实感、细腻纹理和丰富的风格表现。目前,Krea 1 已开放免费 Beta 测试,用户可以体验其强大的图像生成能力。(来源: _akhaliq, op7418)
NVIDIA 发布可定制开源人形机器人模型 GR00T N1: NVIDIA 推出了 GR00T N1,这是一款可定制的开源人形机器人模型。此举旨在推动人形机器人领域的研究与发展,为开发者提供一个灵活的平台来构建和实验各种机器人应用。GR00T N1 的开源特性预计将吸引更广泛的社区参与,加速人形机器人技术的进步。(来源: Ronald_vanLoon)
RoboBrain 2.0 发布7B和32B多模态机器人模型: RoboBrain 2.0 发布了其7B和32B参数的多模态机器人模型,旨在提升机器人在感知、思考和执行任务方面的能力。新模型支持交互式推理、长时规划、闭环反馈、精确的空间感知(点和边界框预测)、时间感知(未来轨迹估计)以及通过实时结构化记忆构建和更新实现的场景推理。这些能力的提升有望推动机器人在复杂环境中的自主操作和决策水平。(来源: Reddit r/LocalLLaMA)
Kling AI 将在CVPR 2025分享视频生成模型最新研究: Kling AI视频生成模型负责人Pengfei Wan将在计算机视觉顶级会议CVPR 2025上发表题为“Kling简介及我们对更强大视频生成模型的研究”的主题演讲。他将与来自Google DeepMind等机构的专家共同探讨视频生成技术的最新突破和前沿进展。此次分享将深入介绍Kling在推动视频生成技术发展方面的成果。(来源: Kling_ai)
AI技术助力2025年中国高考,多地启用智能巡查系统: 2025年中国高考广泛采用AI智能巡查系统,天津、江西、湖北、广东阳江等多地考场实现AI监考全覆盖。这些系统利用4K摄像头、骨骼追踪、人脸识别、音频监测等技术,实时检测考生违规行为,如提前作答、传递物品、交头接耳、视线异常偏离等,并能发出预警。此举旨在提升考试公平性,确保考场纪律。AI监考系统的应用标志着考试管理进入智能化时代,对传统监考方式带来变革。(来源: 36氪)
Gemma 3n 桌面端模型发布,支持跨平台与IoT设备: 谷歌发布了 Gemma 3n 桌面端模型,包括20亿和40亿参数版本,专为桌面(Mac/Windows/Linux)和物联网(IoT)设备优化。该模型由新的 LiteRT-LM 库驱动,旨在提供高效的本地运行能力。开发者可通过Hugging Face预览和GitHub获取相关资源,进一步推动轻量级AI模型在边缘设备上的应用。(来源: ClementDelangue, demishassabis)
🧰 工具
Yutori AI 推出 Scouts:实时网络监控AI代理: 由前Meta AI研究员创立的Yutori AI发布了名为Scouts的AI代理产品。Scouts能够根据用户设定的主题或关键词,实时监控互联网信息,并在相关内容出现时通知用户。该工具旨在帮助用户从繁杂的网络信息中筛选出对自己有价值的内容,例如追踪特定领域的新闻动态、市场趋势、产品优惠、甚至是稀缺预订等。Scouts的推出标志着个性化信息获取工具的进一步发展,让AI成为用户的数字“侦察兵”。(来源: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit推出新功能:将Figma等设计稿一键转化为功能性应用: Replit 发布了 Replit Import 功能,允许用户将来自 Figma、Lovable、Bolt 等平台的设计稿直接导入并转化为可运行的应用程序。该功能旨在降低开发门槛,使非程序员也能快速将设计想法变为现实。Replit Import 支持保持设计保真度,并内置安全扫描和密钥管理,结合 Replit Agent、数据库、认证和托管服务,可创建全栈应用。(来源: amasad, pirroh)
Hugging Face 发布 AISheets:将电子表格与数千AI模型结合: Hugging Face 联合创始人Thomas Wolf宣布推出实验性产品AISheets,该工具将电子表格的易用性与数千个开源AI模型(特别是LLM)的强大功能相结合。用户可以在熟悉的电子表格界面中构建、分析和自动化数据处理任务,利用AI模型进行数据洞察和任务自动化,旨在提供一个快速、简单且功能强大的数据分析新方式。(来源: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex 支持将Agent转换为MCP服务器与Claude等模型交互: LlamaIndex宣布支持将其任何Agent转换为模型上下文协议(MCP)服务器。通过示例代码和视频,展示了如何将自定义的FidelityFundExtraction工作流(用于从复杂PDF中提取结构化数据)部署为MCP服务器,并从Claude模型中调用。这一功能旨在提升工具的智能体化水平,方便与Claude Desktop、Cursor等MCP客户端集成,简化了将现有工作流接入更广泛AI生态系统的过程。(来源: jerryjliu0)
GPT Researcher 集成 LangChain 模型上下文协议 (MCP): GPT Researcher 现已利用 LangChain 的模型上下文协议 (MCP) 适配器进行智能工具选择和研究。该集成将 MCP 与网络搜索功能无缝结合,以实现全面的数据收集。用户可以查阅相关集成文档,了解如何配置和使用这一新功能,从而提升研究效率和深度。(来源: hwchase17)
Tesslate 发布 UIGEN-T3 系列UI生成模型,支持多种尺寸: Tesslate 团队推出了 UIGEN-T3 系列UI生成模型,包括32B、14B、8B和4B等多种参数规模。这些模型专为生成UI组件(如面包屑、按钮、卡片)和完整前端代码(如登录页、仪表盘、聊天界面)而设计,支持Tailwind CSS。模型在Hugging Face上提供,旨在帮助开发者快速构建用户界面。开发者反馈,标准量化会显著降低模型质量,建议在BF16或FP8下运行以获得最佳效果。(来源: Reddit r/LocalLLaMA)
豆包·播客模型发布,一键生成拟人化AI播客: 火山引擎发布了豆包·播客模型,该模型能够根据用户输入的文本(如文章链接或Prompt)快速生成具有高度拟人化对话风格的播客。模型生成的音频在语气、停顿、口语化表达方面接近真人,甚至能根据内容进行有观点的讨论。该技术基于字节跳动语音技术团队的端到端实时语音模型,实现了语音模态上的直接理解和推理。目前,该功能已在豆包PC版和扣子空间上线,旨在降低音频内容创作门槛,提供高效、个性化的信息获取方式。(来源: 量子位)

Unsloth AI 提供 Magistral-Small-2506 的 GGUF 量化版本: 针对 Mistral AI 新发布的 Magistral-Small-2506 推理模型,Unsloth AI 提供了 GGUF 量化版本。这使得用户可以在本地,例如仅需32GB RAM的设备上运行这个240亿参数的模型。此举降低了高性能推理模型的硬件门槛,方便更广泛的开发者和研究者在本地环境中体验和使用 Magistral 模型。(来源: ImazAngel)
📚 学习
LLaVA-1.5 视觉助手构建技术深度解析: LearnOpenCV 发布了一篇关于 LLaVA-1.5 架构的技术深度剖析文章。文章详细介绍了 LLaVA-1.5 如何构建最先进的AI视觉助手,包括其突破性的视觉指令微调技术(Visual Instruction Tuning)以及改变了多模态AI领域的开源数据集。这篇指南对AI/ML工程师和研究人员理解多模态大语言模型的工作原理和训练方法具有重要参考价值。(来源: LearnOpenCV)
蛋白质机器学习入门指南发布: DL Weekly 分享了一篇面向初学者的蛋白质机器学习综合指南。该指南涵盖了蛋白质相关的基本数据类型、深度学习模型、计算方法以及基础生物学概念,旨在帮助对该交叉领域感兴趣的研究人员和开发者快速入门。(来源: dl_weekly)
Qdrant与DataTalksClub合作推出免费RAG与向量搜索课程: Qdrant宣布与DataTalksClub合作,提供为期10周的免费在线课程。课程内容包括检索增强生成(RAG)、向量搜索、混合搜索、评估方法等,并包含一个端到端项目实践。Qdrant的专家Kacper Łukawski和Daniel Wanderung将亲自授课,旨在帮助学习者掌握构建高级AI应用的实用技能。(来源: qdrant_engine)
Weaviate播客探讨LLM结构化输出与约束解码: Weaviate播客最新一期邀请了dottxt.ai的Will Kurt和Cameron Pfiffer,与主持人Connor Shorten一同探讨了大型语言模型(LLM)的结构化输出问题。节目深入讨论了如何通过约束解码技术确保LLM生成可靠、可预测的结果(如有效的JSON、邮件、推文等),而不仅仅是简单的JSON格式校验。他们还介绍了开源工具Outlines及其在实际AI用例中的应用,展望了该技术对未来AI系统的影响。(来源: bobvanluijt)
ACL2025NLP论文SynthesizeMe!:从用户交互中生成个性化提示: 一篇名为 “SynthesizeMe!” 的ACL 2025 NLP会议论文提出了一种新方法,通过分析用户与AI的交互(包括隐式和显式反馈)来创建自然语言的个性化用户模型。该方法首先生成并验证解释用户偏好的推理过程,然后从中归纳出合成的用户画像,并筛选信息丰富的先前用户交互,最终为特定用户构建个性化提示,以期提升LLM的个性化奖励建模和响应能力。DSPy也转发并提及这是dspy.MIPROv2的一个优秀应用案例。(来源: lateinteraction, stanfordnlp)
新论文探讨测试时扩展(Test-Time Scaling)LLM的监控与超频: 一篇新论文关注了如o3、DeepSeek-R1等模型采用的测试时扩展技术,该技术允许LLM在回答前进行更多推理,但用户往往无法了解其内部进度或进行控制。研究者提出暴露LLM的内部“时钟”,并展示了如何监控其推理过程及对其进行“超频”以加速。这为理解和优化大型推理模型的效率提供了新思路。(来源: arankomatsuzaki)
论文提出CARTRIDGES:通过离线自学习压缩长上下文LLM的KV缓存: 斯坦福大学HazyResearch的研究者提出了一种名为CARTRIDGES的新方法,旨在解决长上下文LLM中KV缓存占用内存过高的问题。该方法通过一种“自学习”的测试时训练机制,离线训练一个较小的KV缓存(称为cartridge)来存储文档信息,从而在保持任务性能的同时,平均减少39倍的缓存内存并提升26倍的峰值吞吐量。这种cartridge训练一次后可被不同用户请求复用,为长上下文处理提供了新的优化思路。(来源: gallabytes, simran_s_arora, stanfordnlp)
新论文Grafting:低成本实现预训练扩散Transformer架构编辑: 斯坦福大学的研究者提出了一种名为Grafting的新方法,用于编辑预训练的扩散Transformer模型架构。该技术允许以仅占预训练成本2%的计算量,将模型中的注意力机制等替换为新的计算原语,从而在小计算预算下实现对模型架构的定制化设计。这对探索新的模型架构和提升现有模型效率具有重要意义。(来源: realDanFu, togethercompute)
ICML新论文:平均检查点方法在AlgoPerf基准上加速模型训练: 一篇新的ICML论文研究了平均检查点(Averaging Checkpoints)这一经典方法在提升机器学习模型训练速度和性能方面的应用。研究者们在AlgoPerf这一结构化、多样化的优化算法基准上测试了该方法,探讨其在不同任务上的实际效益,为加速模型训练提供了实践参考。(来源: aaron_defazio)
Transformer可视化解释工具开源: DL Weekly介绍了一款交互式可视化工具,旨在帮助用户理解基于Transformer架构的模型(如GPT)的工作原理。该工具通过可视化的方式拆解模型内部机制,使复杂的概念更易于理解,适合对Transformer模型感兴趣的学习者和研究人员。项目已在GitHub开源。(来源: dl_weekly)
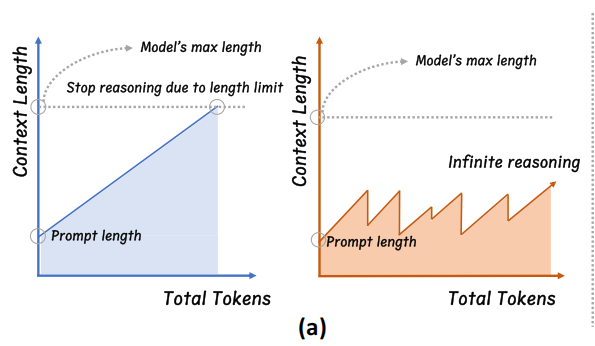
浙大提出InftyThink:分段与总结实现无限深度推理: 浙江大学联合北京大学的研究团队提出了大模型推理新范式InftyThink。该方法将长推理拆分为多个短片段,并在片段间引入总结来衔接上下文,从而理论上实现无限深度推理,同时保持较高生成吞吐量。此方法不依赖模型结构调整,通过重构训练数据为多轮推理格式,与现有预训练、微调流程兼容。实验表明,InftyThink能显著提升模型在AIME24等基准上的性能,并提高生成吞吐。(来源: 量子位)
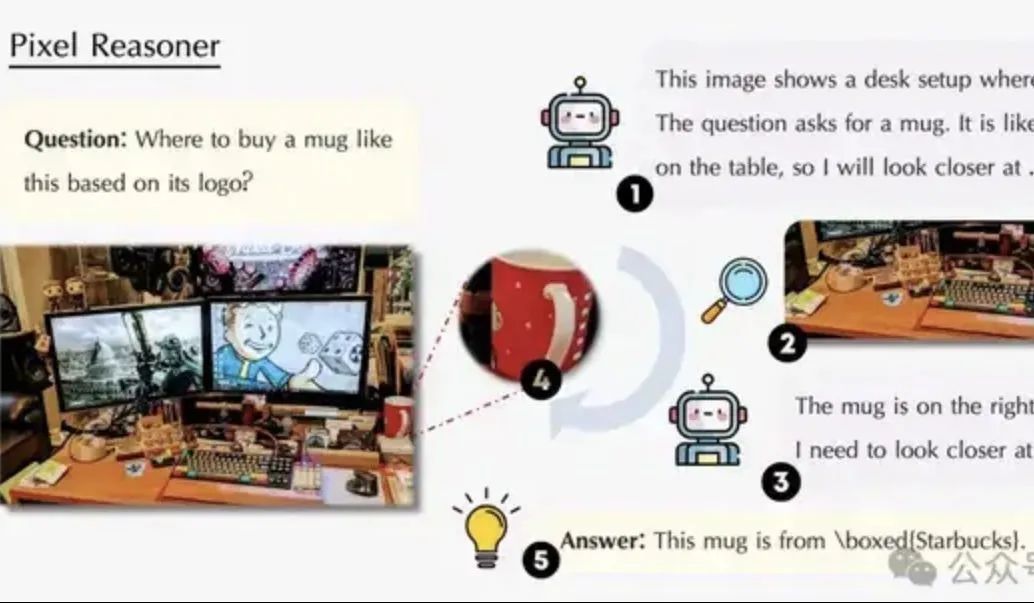
论文探讨像素空间推理:让VLM像人类一样“眼脑并用”: 滑铁卢大学、港科大、中科大的研究团队提出“像素空间推理”(Pixel-Space Reasoning)范式,使视觉语言模型(VLM)能直接在像素级别进行操作和推理,如视觉变焦、时空标记等,而非依赖文本token作为中介。通过内在好奇心激励和外在正确性激励的强化学习方案,克服了模型的“认知惰性”。基于Qwen2.5-VL-7B构建的Pixel-Reasoner在V*Bench等多个基准上表现优异,7B模型性能超越GPT-4o。(来源: 量子位)
DeepLearning.AI推出数据分析专业证书第五门课程:数据故事化: DeepLearning.AI发布了其数据分析专业证书的第五门课程,主题为“数据故事化”。课程教授如何选择合适的媒介(仪表盘、备忘录、演示文稿)呈现洞察,使用Tableau设计交互式仪表盘,将发现与业务目标对齐并有效沟通,以及求职指导。强调数据故事化在提升业务表现和有效传达洞察方面的重要性。(来源: DeepLearningAI)
论文探讨知识冲突对大语言模型的影响: 一篇新论文系统评估了大型语言模型(LLM)在面临上下文输入与参数化知识(即模型内部“记忆”)冲突时的行为。研究发现,知识冲突对不依赖知识利用的任务影响甚微;当上下文与参数知识一致时,模型表现更佳;即使被指示,模型也无法完全抑制内部知识;提供解释冲突的理由会增加模型对上下文的依赖。这些发现对基于模型的评估有效性提出了疑问,并强调在部署LLM时需考虑知识冲突问题。(来源: HuggingFace Daily Papers)
论文CyberV:用于视频理解中测试时扩展的控制论框架: 为解决多模态大语言模型(MLLM)在处理长视频或复杂视频时面临的计算需求、鲁棒性和准确性问题,研究者提出CyberV框架。该框架受控制论原理启发,将视频MLLM重新设计为自适应系统,包含MLLM推理系统、传感器和控制器。传感器监控模型前向过程并收集中间解释(如注意力漂移),控制器决定何时以及如何触发自我校正并生成反馈。该测试时自适应扩展框架无需重训练即可增强现有MLLM,实验表明其在VideoMMMU等基准上显著提升了Qwen2.5-VL-7B等模型的性能。(来源: HuggingFace Daily Papers)
论文提出LoRMA:用于LLM参数高效微调的低秩乘法自适应: 为解决现有基于LoRA和MoE的参数高效微调(PEFT)方法中存在的表示崩溃和专家负载不平衡问题,研究者提出了低秩乘法自适应(LoRMA)。该方法将PEFT适配器专家的更新方式从加法转变为更丰富的矩阵乘法变换,通过有效重排操作和引入秩膨胀策略来应对计算复杂性和秩瓶颈。实验证明,MoA(混合适配器)异构方法在性能和参数效率上均优于同构MoE-LoRA方法。(来源: Reddit r/MachineLearning)
论文提出FlashDMoE:单核快速分布式MoE实现: 研究者推出了FlashDMoE,这是首个将分布式混合专家(MoE)前向传播完全融合到单个CUDA核心的系统。通过从头用纯CUDA编写融合层,FlashDMoE实现了高达9倍的GPU利用率提升、6倍的延迟降低以及4倍的弱扩展效率改进。该工作为优化大规模MoE模型的推理效率提供了新的思路和实现。(来源: Reddit r/MachineLearning)
💼 商业
xAI 与 Polymarket 合作,融合市场预测与 Grok 分析: Elon Musk 旗下的人工智能公司 xAI 宣布与去中心化预测市场平台 Polymarket 建立合作伙伴关系。此次合作旨在将 Polymarket 的市场预测数据与 X (前 Twitter) 的数据以及 Grok AI 的分析能力相结合,打造一个“硬核真相引擎”,以揭示塑造世界的因素。xAI 表示这仅仅是合作的开始,未来将有更多合作内容。(来源: xai)
AI推理芯片公司Groq获沙特15亿美元投资承诺,专注垂直整合策略: AI推理芯片公司Groq宣布获得沙特阿拉伯15亿美元的投资承诺,用于扩大其基于LPU(语言处理单元)的AI推理基础设施在当地的交付规模。Groq由TPU发明者之一Jonathan Ross创立,专注于AI推理计算,其LPU芯片采用可编程流水线架构,内存和计算单元集成在同一芯片上,大幅提升数据存取速度和能效。Groq不仅销售芯片,更提供GroqRack集群(私有云/AI计算中心)和GroqCloud云平台(Tokens-as-a-Service),并支持Llama、DeepSeek、Qwen等主流开源模型。公司还开发了Compound复合AI系统,提升AI推理云价值。(来源: 36氪)
深圳人形交互机器人公司“数字华夏”完成数千万元天使+轮融资: 数字华夏(深圳)科技有限公司近日完成数千万元天使+轮融资,由同创伟业独家投资。该公司聚焦AGI机器人规模商用,核心产品包括仿人机器人“夏澜”、通用人形机器人“夏起”和IP系列机器人“星行侠”。“夏澜”机器人以精密仿生技术为核心,能模仿人类绝大部分表情,并具备多模态交互能力。公司已获得数亿元订单,客户包括头部ICT厂商、地方电网等。(来源: 36氪)
🌟 社区
Sam Altman发表博文《温柔的奇点》,探讨AI的渐进式革命与未来: OpenAI CEO Sam Altman 发表博文,认为技术奇点正以一种比预想更平缓、“温柔”的方式悄然发生,是一个持续、指数级加速的渐进过程。他预测2025年能独立完成复杂脑力工作(如编程)的AI智能体将重塑软件业,2026年可能出现能发现全新科学见解的系统,2027年能在现实世界完成任务的机器人或将出现。Altman强调,解决AI对齐问题和确保技术普惠是通往繁荣未来的关键。他还透露,OpenAI的首个开源权重模型将推迟至夏末发布,因研究团队取得了“意料之外的惊人成果”。(来源: dotey, scaling01, sama)
社区热议OpenAI o3-pro:性能强大但成本高昂,o3降价引发连锁反应: OpenAI o3-pro的发布及其高昂定价(输出$80/M tokens)成为社区讨论焦点。用户普遍认可其在复杂推理、编程等任务上的强大能力,但也对其响应速度和成本表示关切,有用户戏称简单问候“Hi”就可能花费80美元。同时,o3模型大幅降价80%被视为可能引发AI模型价格战,对标GPT-4o及其他竞品。社区对o3降价后性能是否“降智”存在争议。OpenAI随后宣布将ChatGPT Plus用户的o3使用额度翻倍,以回应用户需求。(来源: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Meta高额薪酬引才与AI组织资金投入引热议: Meta为AI研究员提供的高额薪酬包(据称达九位数美元)引发社区讨论。Nat Lambert评论指出,这样的薪酬或许可以资助一个像AI2规模的整个研究机构,暗示了顶级人才成本之高昂。结合Meta成立“超级智能实验室”并巨资投入Scale AI的举动,社区普遍认为Meta正不惜代价重塑其AI竞争力,但也关注其内部组织政治和效率问题。Helen Toner转发的ChinaTalk内容指出,Meta此举是为打破组织内部的政治和自负问题。(来源: natolambert, natolambert)
苹果WWDC新UI风格“液态玻璃”引设计与可用性讨论: 苹果在WWDC 2025上推出的新UI设计风格“液态玻璃”(Liquid Glass)在开发者和设计师社区中引发广泛讨论。部分观点认为其视觉效果新颖,体现了苹果向3D界面设计的探索。然而,ID_AA_Carmack(John Carmack)等资深人士指出,半透明UI通常在可用性方面存在问题,易产生视觉干扰和低对比度,影响阅读和操作,并提及Windows和Mac历史上也曾尝试类似设计但最终因可用性问题而调整。用户体验(UX)应优先于用户界面(UI)的视觉效果成为讨论核心。(来源: gfodor, ID_AA_Carmack, ReamBraden, dotey)
AI辅助编程实践:敏捷迭代优于一次性生成: 社交媒体上,dotey针对使用AI(如Claude Code)进行编程的最佳实践发表观点。他认为,不应采用一次性提供完整需求让AI生成庞大半成品(瀑布模型)或先生成不完善产品再优化(类似图中第三种模式)的方式,因为这难以控制质量且后期维护困难。他提倡采用敏捷迭代模式(类似图中第一种模式),将大型项目(如ERP系统)拆分为多个可独立稳定运行的小版本,逐步迭代开发,确保每个版本的功能完整性和可控性,这与传统软件工程的最佳实践一致。(来源: dotey)
Mustafa Suleyman:AI技术正从固定统一向动态个性化演进: Inflection AI及前DeepMind联合创始人Mustafa Suleyman评论指出,传统技术通常是固定的、统一的、“一刀切”的模式,而当前的人工智能技术则呈现出动态、个性化和涌现性的特征。他认为这意味着技术正从提供单一重复结果向探索无限可能性路径转变,强调了AI在个性化服务和创造性应用方面的巨大潜力。(来源: mustafasuleyman)
Perplexity AI遭遇基础设施问题,CEO出面解释: Perplexity AI的CEO Arav Srinivas在社交媒体上回应用户关于服务不稳定的问题,表示由于基础设施问题,不得不为部分流量启用了降级用户体验(degraded UX)。他强调用户的数据(如library或threads)并未丢失,一旦系统稳定,所有功能将恢复正常。这反映了AI服务在快速发展过程中,基础设施的稳定性和可扩展性面临的挑战。(来源: AravSrinivas)
Sergey Levine探讨语言模型与视频模型的学习差异: UC伯克利教授Sergey Levine在其文章《柏拉图洞穴中的语言模型》中提出一个深刻问题:为何语言模型能从预测下一个词中学到很多,而视频模型从预测下一帧中学到的却相对较少?他认为,LLM通过学习人类知识的“影子”(文本数据)获得了强大的推理能力,这更像是对人类认知的“逆向工程”,而非真正自主探索物理世界。视频模型直接观察物理世界,但目前在复杂推理上不及LLM。他提出,AI的长期目标应是突破对人类知识“影子”的依赖,通过传感器直接与物理世界交互,实现自主探索。(来源: 36氪)
💡 其他
AI伦理与意识探讨:AI能否拥有真正的意识?: MIT Technology Review关注AI意识的复杂议题。文章指出,AI意识不仅是智力难题,更是具道德分量的议题。错误判断AI意识可能导致无意中奴役有感知能力的AI,或为无感知机器牺牲人类福祉。研究界在理解意识本质上已取得进展,这些成果或为探索和应对人工意识提供指引。这引发了关于AI权利、责任以及人机关系的深层思考。(来源: MIT Technology Review)
图灵奖得主Joseph Sifakis:当前AI非真智能,需警惕知识与信息混淆: 图灵奖得主Joseph Sifakis在其著作及访谈中指出,当前社会对AI的理解存在偏差,混淆了信息堆砌与智慧创造,高估了机器“智能”。他认为目前尚无真正的智能系统,AI对工业的实际影响甚微。AI缺乏常识理解,其“智能”是统计模型的产物,难以在复杂社会情境中权衡价值与风险。他强调教育核心是培养批判思维与创造力,而非知识传递,并呼吁建立AI应用全球标准,明确责任边界,使AI成为增强人类的伙伴而非替代品。(来源: 36氪)
AI时代广告业重构:从创意生成到个性化投放的变革: 谷歌I/O 2025大会展示了AI如何深度重构广告行业。趋势包括:1) AI驱动创意自动化,从图片到视频脚本均可由AI生成,如Veo 3、Imagen 4和Flow等工具降低了高质量内容创作门槛。2) 个性化范式从“千人千面”转向“一人千面”,AI智能代理能主动理解用户需求并促成交易。3) 广告与内容界限模糊,广告直接融入AI生成的搜索结果,成为信息的一部分。品牌主需构建专属智能体、提供面向AI的服务,并坚持“品效合一”的长期策略以适应变革。(来源: 36氪)
本篇文章来源于微信公众号: AI热点掘金 ,仅供学习,如有侵权请及时联系删除
